Sprawdzanie ważności danych. Prawidłowy kod HTML Prawidłowe żądania
Do tej pory przyglądaliśmy się poszczególnym fragmentom kodu HTML. Ale dokument HTML (lub strona internetowa, co oznacza to samo) wymaga określonej struktury, aby był ważny.
Dlaczego zależy nam na walidacji dokumentów HTML?
- Poprawność: Prawidłowy dokument jest poprawnie wyświetlany w przeglądarce.
- Debugowanie: Zły kod HTML może powodować błędy trudne do wykrycia.
- Łatwość konserwacji: ważny dokument jest łatwiejszy do późniejszej aktualizacji, nawet dla kogoś innego.
Pierwszą informacją, którą piszemy jest typ Dokument HTML - typ dokumentu.
Pomyśl o dokumencie jako o wersji samochodu na przestrzeni lat: Ford Fiesta, który kupiłeś w 1986 roku, był Fiestą 2. Jeśli kupisz go dzisiaj, będzie to Fiesta 7.
Wcześniej współistniało kilka wersji HTML (XHTML i HTML 4.01 były konkurencyjnymi standardami). Obecnie HTML5 jest normą.
Aby poinformować przeglądarkę, że dokument HTML to HTML5, po prostu rozpocznij dokument następującym wierszem:
To wszystko. Po prostu zainstaluj i zapomnij o tym.
Być może zastanawiasz się, dlaczego w tym dokumencie HTML5 nie wspomniano o liczbie 5. W3C uznała, że poprzednie definicje typu dokumentu były zbyt zagmatwane i skorzystała z okazji, aby go uprościć, usuwając wzmiankę o wersji HTML.
ElementOprócz linii doctype cały dokument HTML powinien znajdować się wewnątrz elementu:
jest technicznie przodkiem wszystkich elementów HTML.
Jak przenoszone są atrybuty dodatkowe informacje w przypadku elementu HTML zawiera on także dodatkowe informacje dotyczące całej strony internetowej.
Przykładowo tytuł strony (wyświetlany w zakładce) ma postać:
Mój fantastyczny blog
Następujące elementy HTML mogą pojawiać się w i tylko w:
Chociaż zawiera tylko metadane, które w ogóle nie są przeznaczone do wyświetlania (z wyjątkiem ), w tym elemencie zapisujemy całą naszą treść. Wszystko, co jest w środku, zostanie wyświetlone w oknie przeglądarki.
W pełni prawidłowy dokument HTMLŁącząc wszystkie te wymagania, możemy napisać prosty i poprawny dokument HTML:
Arkusz Marka
Witaj świecie!
Jeśli obejrzysz ten przykład w przeglądarce, zobaczysz, że:
- „MarkSheet” jest zapisany na karcie przeglądarki;
- „Witaj, świecie!” to jedyny tekst wyświetlany w oknie, ponieważ jest to jedyna treść.
W3C oferuje usługę sprawdzania poprawności znaczników, która pozwala sprawdzić dowolny dokument HTML pod kątem błędów i ostrzeżeń.
Sprawdzanie ważności kodu HTML witryny jest koniecznie zawarte w moim pliku . Ale nie ma co przeceniać znaczenia błędów walidacyjnych w promocji SEO – jest ono bardzo małe. Dla każdego tematu w TOP będą strony z dużą liczbą takich błędów i będą one działać dobrze.
ALE! Brak błędów technicznych na stronie jest czynnikiem rankingowym, dlatego nie należy lekceważyć tej okazji. Lepiej to naprawić, na pewno nie będzie gorzej. Wyszukiwarki zobaczą Twoje wysiłki i dadzą Ci mały plus w Twojej karmie.
Jak sprawdzić witrynę pod kątem ważności kodu HTMLWalidacja kodu witryny jest sprawdzana za pomocą usługa internetowa Walidator HTML W3C. Jeśli wystąpią błędy, usługa wyświetli listę. Teraz przeanalizuję najczęstsze rodzaje błędów, które napotkałem na stronach.
- Błąd: zduplikowany identyfikator min_value_62222

Za tym błędem kryje się ostrzeżenie.
- Ostrzeżenie: tutaj miało miejsce pierwsze wystąpienie identyfikatora min_value_62222

Oznacza to, że duplikowany jest identyfikator stylu ID, który zgodnie z zasadami ważności HTML musi być unikalny. Zamiast ID możesz użyć CLASS dla zduplikowanych obiektów.
Skorygowanie tego jest pożądane, ale niezbyt krytyczne. Jeśli takich błędów jest dużo, lepiej je poprawić.
Podobnie mogą istnieć inne opcje:
- Błąd: zduplikowany identyfikator placeWorkTimes
- Błąd: zduplikowany identyfikator wywołania zwrotnegoCss-css
- Błąd: zduplikowany identyfikator Capa_1
Poniżej znajduje się bardzo częste ostrzeżenie.
- Ostrzeżenie: atrybut type jest niepotrzebny w przypadku zasobów JavaScript
Jest to bardzo częsty błąd podczas sprawdzania poprawności witryny. Zgodnie z regułami HTML5 atrybut type nie jest potrzebny dla znacznika skryptu; jest to element przestarzały.
Podobne ostrzeżenie dla stylów:
- Ostrzeżenie: Atrybut type elementu stylu nie jest potrzebny i należy go pominąć
Korygowanie tych ostrzeżeń jest pożądane, ale nie krytyczne. Na duże ilości lepiej to naprawić.
- Ostrzeżenie: Rozważ unikanie wartości rzutni, które uniemożliwiają użytkownikom zmianę rozmiaru dokumentów
To ostrzeżenie wskazuje, że nie można zwiększyć rozmiaru strony na telefonie komórkowym lub tablecie. Oznacza to, że użytkownik chciał przyjrzeć się bliżej obrazom lub bardzo małemu tekstowi i nie może tego zrobić.
Uważam, że to ostrzeżenie jest bardzo niepożądane, jest niewygodne dla użytkownika i jest minusem ze względów behawioralnych. Wyeliminowane poprzez usunięcie tych elementów - maksymalna skala = 1,0 i skalowalność użytkownika = nie.
- Błąd: określono atrybut itemprop, ale element nie jest właściwością żadnego elementu
To jest mikroznacznik, atrybut itemprop musi znajdować się wewnątrz elementu z itemscope. Myślę, że ten błąd nie jest krytyczny i można go pozostawić bez zmian.
- Ostrzeżenie: w dokumentach nie należy używać about:legacy-compat, chyba że są wygenerowane przez starsze systemy, które nie mogą wygenerować standardowego typu dokumentu
Linia about:legacy-compat jest potrzebna tylko w przypadku generatorów HTML. Tutaj po prostu musisz to zrobić, ale błąd wcale nie jest krytyczny.
- Błąd: bezpańskie źródło tagu końcowego

Jeśli zajrzysz do kodu samej witryny i znajdziesz ten element, zobaczysz, że pojedynczy tag jest zapisany jako para - nie jest to poprawne.
W związku z tym należy usunąć znacznik zamykający z kodu. Podobnie jak w przypadku tego błędu, mogą wystąpić tagi
- Błąd: element img musi mieć atrybut alt, z wyjątkiem pewnych warunków. Aby uzyskać szczegółowe informacje, zapoznaj się ze wskazówkami dotyczącymi zapewniania alternatywnych tekstów dla obrazów
Wszystkie obrazy muszą mieć atrybut alt. Uważam ten błąd za krytyczny i należy go naprawić.
- Błąd: Element ol nie jest dozwolony jako element podrzędny elementu ul w tym kontekście. (Pomijanie dalszych błędów z tego poddrzewa.)

Zagnieżdżanie tagów jest tutaj nieprawidłowe. W
- powinno być tylko
- . W tym przykładzie elementy te w ogóle nie są potrzebne.

Podobnie mogą występować inne błędy, takie jak ten:
- Element h2 nie jest dozwolony jako element podrzędny elementu ul w tym kontekście.
- Element a nie jest dozwolony jako element podrzędny elementu ul w tym kontekście.
- Element noindex nie jest dozwolony jako element potomny elementu li w tym kontekście.
- Element div nie jest dozwolony jako element podrzędny elementu ul w tym kontekście.
To wszystko wymaga korekty.
- Błąd: atrybut http-equiv nie jest w tym momencie dozwolony w elemencie meta
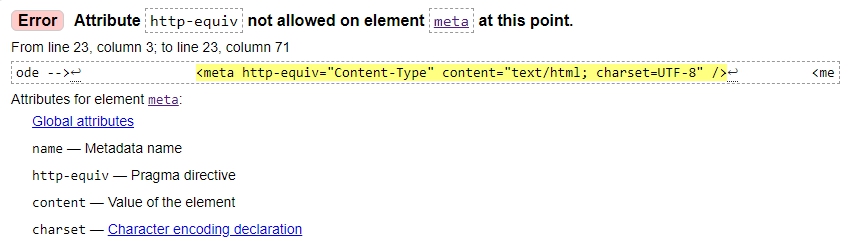
Atrybut http-equiv nie jest przeznaczony dla elementu meta, należy go usunąć lub zastąpić.
Podobne błędy:
- Błąd: Atrybut n2-lightbox nie jest w tym momencie dozwolony w elemencie a.
- Błąd: atrybut asyncsrc nie jest w tym momencie dozwolony w skrypcie elementu.
- Błąd: cena atrybutu nie jest w tym momencie dozwolona w opcji elementu.
- Błąd: ciąg znaków atrybutu nie jest w tym momencie dozwolony w zakresie elementu.
Tutaj musisz także usunąć atrybuty n2-lightbox, asyncsrc, cena, hashstring lub zastąpić je innymi opcjami.
- Błąd: zły tag początkowy w obrazie w głowie
Lub tak:
- Błąd: zły znacznik początkowy w div w głowie

Tagi Img i div nie powinny znajdować się w plikach . Ten błąd wymaga naprawienia.
- Błąd: CSS: błąd analizy

W w tym przypadku W stylach nie powinno być średnika po nawiasie.
No cóż, taki błąd, drobnostka, ale nieprzyjemna) Przekonaj się sam, czy trzeba go usunąć, czy nie, nie będzie to miało żadnego wpływu na promocję strony.
- Ostrzeżenie: atrybut charset elementu skryptu jest przestarzały
Nie ma już potrzeby określania kodowania w skryptach; jest to element przestarzały. Ostrzeżenie nie jest krytyczne, według własnego uznania.
- Błąd: Skrypt elementu nie może mieć atrybutu charset, chyba że określono również atrybut src
W przypadku tego błędu należy usunąć atrybut charset="uft-8" ze skryptu, ponieważ pokazuje on kodowanie poza skryptem. Uważam, że ten błąd trzeba naprawić.
- Ostrzeżenie: pusty nagłówek

Oto pusty nagłówek h1. Musisz usunąć tagi lub umieścić tytuł pomiędzy nimi. Błąd jest krytyczny.
- Błąd: znacznik końcowy br

Znacznik br jest pojedynczy, ale jest wykonany tak, jakby zamykał parę. Musimy usunąć / z tagu.
- Błąd: nazwane odwołanie do znaku nie zostało zakończone średnikiem. (Lub & powinien zostać zmieniony jako &.)

To są specjalne znaki HTML, musisz je poprawnie zapisać lub &skopiować. Lepiej naprawić ten błąd.
- Błąd krytyczny: Nie można odzyskać danych po ostatnim błędzie. Wszelkie dalsze błędy będą ignorowane
To poważny błąd:
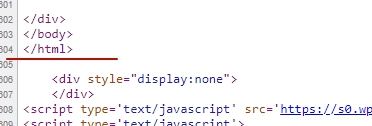
Po nim nie powinno być nic, ponieważ jest to ostatni tag zamykający stronę. Musisz usunąć wszystko po nim lub przenieść wyżej.
- Błąd: CSS: prawda: tylko 0 może być jednostką. Po liczbie należy umieścić jednostkę
Musisz wpisać wartość w px:

Oto podobny błąd:
- Błąd: CSS: margines na górze: tylko 0 może być jednostką. Po liczbie należy umieścić jednostkę
- Błąd: Niezamknięty element a
Wykonuje kilka kontroli Twojego kodu. Główne:
- Walidacja składni - sprawdzanie błędów składniowych.
- jest poprawną składnią, nawet jeśli nie jest prawidłowym znacznikiem HTML, więc sprawdzanie składni jest minimalnie przydatne przy pisaniu dobrego kodu HTML.
- Sprawdzanie zagnieżdżenia tagów - tagi należy zamykać w odwrotnej kolejności w stosunku do ich otwierania. Na przykład to sprawdzenie wychwytuje błędy z .
- Walidacja DTD - sprawdzanie, czy Twój kod pasuje do określonej definicji typu dokumentu. Obejmuje to sprawdzanie nazw tagów, atrybutów i „osadzania” tagów (tagi jednego typu w tagach innego typu) Należy pamiętać, że są to kontrole logiczne i nie ma znaczenia, w jaki sposób zaimplementowano walidator. Jeśli co najmniej jedno sprawdzenie zakończy się niepowodzeniem, kod HTML zostanie uznany za nieprawidłowy. I w tym tkwi problem. Argumenty Głównym argumentem przemawiającym za walidacją HTML jest zgodność z różnymi przeglądarkami. Każda przeglądarka ma swój własny parser i podanie mu tego, co rozumieją wszystkie przeglądarki, to jedyny sposób, aby mieć pewność, że Twój kod będzie działał poprawnie we wszystkich przeglądarkach. Ponieważ każda przeglądarka ma własny mechanizm korekcji błędów HTML, nie można polegać na nieprawidłowym kodzie.
- prawidłowy kod HTML nie gwarantuje dostępności;
- Poprawny HTML nie gwarantuje dobrego UX (doświadczenia użytkownika);
- Poprawny kod HTML nie gwarantuje funkcjonowania strony internetowej;
- Poprawny kod HTML nie gwarantuje prawidłowego wyświetlania witryny.
- Sprawdzanie błędów składniowych:
Przykład z habrahabr.ru/post/101985:
ma poprawną składnię, mimo że jest nieprawidłowym tagiem HTML
Zatem sprawdzanie składni jest minimalnie przydatne przy pisaniu dobrego kodu HTML. - Sprawdzanie zagnieżdżenia tagów:
W dokumencie HTML znaczniki należy zamykać w kolejności odwrotnej do ich otwierania. Ta kontrola identyfikuje niezamknięte lub nieprawidłowo zamknięte znaczniki. - Walidacja HTML według DTD:
Sprawdzanie, jak dobrze kod pasuje do określonego DTD - Definicja typu dokumentu (doctype). Obejmuje to sprawdzanie nazw tagów, atrybutów i wstawiania tagów (tagi jednego typu wewnątrz tagów innego typu). - Sprawdzanie obecności obcych elementów:
Wykryje wszystko, co jest w kodzie, ale nie w typie dokumentu.
Na przykład niestandardowe tagi i atrybuty. - wygodniej i szybciej - niestandardowe atrybuty dla Javascript/AJAX lub
- Zoptymalizowany pod kątem SEO - znaczniki ARIA.
- OB w plikach szablonów:
Znalezienie i naprawienie ich nie jest trudne.
Jeśli jakieś drobne błędy pomogły uczynić witrynę bardziej funkcjonalną lub szybszą, możesz je opuścić. - OB w skryptach innych firm podłączonych do witryny:
Na przykład widżet VKontakte, skrypt Twittera lub pliki wideo z YouTube.
Nie ma możliwości ich naprawienia, ponieważ te pliki i skrypty znajdują się na innych stronach i nie mamy do nich dostępu. - Reguły CSS, których walidator nie rozumie:
Walidator sprawdza, czy kod witryny pasuje do określonej wersji HTML lub CSS.
Jeśli w swoim szablonie użyłeś reguł CSS w wersji 3, a walidator sprawdza zgodność z wersją 2.1, to wszystkie reguły CSS3 uzna za błędy, choć tak nie jest. - OB, które nieuchronnie należy pozostawić na miejscu, aby uzyskać pożądany rezultat. Na przykład:
- tagi noindex. Nie są one ważne, ale są bardzo potrzebne i trzeba to znosić.
- khaki. Aby strona wyświetlała się poprawnie w niektórych przeglądarkach, czasem trzeba zastosować hacki – kod, który rozumie tylko określona przeglądarka.
- Błędy samego walidatora.
Często nie widzi niektórych tagów (np. zamykających) i raportuje o OB tam, gdzie ich nie ma. - Funkcje WordPress (na przykład the_category()), które generują nieprawidłowy kod.
- Wysyłanie filmów z witryn hostujących wideo, na przykład z YouTube, a w kodzie YouTube znajduje się wiele OV, na które ani Ty, ani ja nie mamy wpływu.
- Pikolak sieci społecznościowe, które są połączone za pomocą skryptów tych sieci i zawierają OV.
- Reguły CSS3 i HTML5 uznawane przez starsze weryfikatory za błędy.
Jednocześnie walidatorzy wersji CSS3 i HTML5 uznają stare reguły za błędy :). - Czasami, aby uzyskać poprawne wyświetlanie w przeglądarce Internet Explorer lub starszych wersjach innych przeglądarek, trzeba zastosować tzw. hacki – kod zrozumiały tylko dla konkretnej przeglądarki, aby napisać reguły wyświetlania strony specjalnie dla tej przeglądarki.
- Waliduj według URI - weryfikacja według adresu
- Validate by File Upload - analiza przesłanego pliku
- Waliduj przez bezpośrednie wprowadzanie - sprawdzanie konkretnego fragmentu kodu.
Głównym argumentem przeciwko walidacji jest to, że jest ona zbyt rygorystyczna i nie odpowiada faktycznemu działaniu przeglądarek. Tak, HTML może być nieprawidłowy, ale wszystkie przeglądarki mogą traktować nieprawidłowy kod w ten sam sposób. Jeśli chcę wziąć odpowiedzialność za zły kod, który piszę, nie muszę się martwić sprawdzaniem. Jedyne o co muszę się martwić to to, że to działa.
Moje stanowisko To jeden z niewielu przypadków, gdy publicznie wypowiadam się na temat mojego stanowiska w jakiejś sprawie. Zawsze byłem przeciwnikiem walidacji, gdyż walidator jest zbyt rygorystyczny, aby był praktyczny w zastosowaniach w świecie rzeczywistym. Są rzeczy obsługiwane przez większość przeglądarek (w, po), które są nieprawidłowe, ale czasami są bardzo potrzebne do prawidłowego działania.Ogólnie rzecz biorąc, moim największym problemem z walidacją jest sprawdzenie #4 (pod kątem obcych elementów). Jestem zwolennikiem używania niestandardowych atrybutów w znacznikach HTML do przechowywania dodatkowych metadanych związanych z konkretnym elementem. W moim rozumieniu jest to np. dodanie atrybutu foo gdy mam dane (pasek), które muszę powiązać z konkretnym elementem. Czasami ludzie przeciążają istniejące atrybuty do tych celów tylko po to, aby przejść weryfikację, nawet jeśli atrybut będzie używany do innych celów. To nie ma dla mnie sensu.
Sekret przeglądarek polega na tym, że nigdy nie sprawdzają, czy kod HTML pasuje do określonego DTD. Typ dokumentu określony w dokumencie przełącza parser przeglądarki w określony tryb, ale nie powoduje to załadowania typu dokumentu i sprawdzenia zgodności kodu z nim. Oznacza to, że parser przeglądarki przetwarza HTML z pewnymi założeniami o nieważności, takimi jak samozamykające się znaczniki i elementy blokowe wewnątrz elementów wbudowanych (jestem pewien, że są inne).
W przypadku atrybutów niestandardowych wszystkie przeglądarki analizują i uznają atrybuty poprawne składniowo za prawidłowe. Umożliwia to dostęp do takich atrybutów poprzez DOM przy użyciu JavaScript. Dlaczego więc miałbym się martwić o ważność? Będę nadal korzystać z moich atrybutów i bardzo się cieszę, że HTML5 je formalizuje.
Najlepszym przykładem technologii, która skutkuje nieprawidłowym kodem HTML, ale robi ogromną różnicę, jest ARIA. ARIA działa poprzez dodanie nowych atrybutów do HTML 4. Atrybuty te nadają dodatkowe znaczenie semantyczne elementom HTML, a przeglądarka jest w stanie przekazać tę semantykę do urządzeń wspomagających, aby pomóc osobom niepełnosprawnym. Wszystkie główne przeglądarki obsługują teraz znaczniki ARIA. Jeśli jednak użyjesz tych atrybutów, będziesz mieć nieprawidłowy kod HTML.
Jeśli chodzi o tagi niestandardowe, myślę, że nie ma nic złego w dodawaniu do strony nowych tagów o poprawnej składni, ale nie widzę w tym zbytniej praktycznej wartości.
Aby moje stanowisko było jasne: uważam, że kontrole nr 1 i 2 są bardzo ważne i zawsze należy je przeprowadzać. Uważam również, że kontrola nr 3 jest ważna, ale nie tak ważna jak pierwsze dwa. Kontrola nr 4 jest dla mnie bardzo wątpliwa, ponieważ wpływa na atrybuty niestandardowe. Uważam, że atrybuty niestandardowe powinny być oznaczone w wynikach walidacji maksymalnie jako ostrzeżenia (a nie błędy), aby móc sprawdzić, czy wprowadziłem niepoprawną nazwę atrybutu. Możliwe jest oznaczanie tagów niestandardowych jako błędów dobry pomysł, ale ma też pewne problemy, na przykład przy osadzaniu treści w innych znacznikach - SVG lub MathML.
Walidacja dla samej walidacji? Uważam, że walidacja dla samej walidacji jest wyjątkowo głupia. Prawidłowy kod HTML oznacza tylko, że wszystkie 4 kontrole przeszły bez błędów. Jest kilka ważnych rzeczy, których prawidłowy kod HTML nie gwarantuje:Wiem, że dla wielu jest to temat kontrowersyjny, dlatego proszę powstrzymać się od wypowiedzi czysto emocjonalnych w komentarzach.
UPD: dzięki za karmę, przeniosłem ją do tematycznej. Powtórzę słowa autora: Rozumiem, że jest to temat kontrowersyjny, ale proszę o powstrzymanie się od komentarzy czysto emocjonalnych i przedstawienie argumentów.
Ostatnio otrzymałem kilka pytań od użytkowników dotyczących ważności moich motywów i ogólnej walidacji. W tym poście chcę na nie odpowiedzieć.
Co to jest ważność? Uważa się, że ważność kodu jest pojedynczą, uniwersalną cechą każdego kodu.
Uważa się, że ważność kodu jest pojedynczą, uniwersalną cechą każdego kodu.
Tak naprawdę ważność to zgodność kodu HTML dokumentu z pewnym zestawem reguł określonych w typie dokumentu lub implikowanych w HTML5.
Oznacza to, że ważność jest pojęciem względnym, ponieważ zasady są różne, podobnie jak ich wymagania.
Aby było jaśniej, podam przykład, który znalazłem na stronie css-live.ru:
W stronę budownictwa budynki mieszkalne i elektrownie jądrowe stosuje się różne SNiP ( kody budowlane i zasady), więc dokument ważny według jednego zbioru zasad, może nie być ważny według innego (fajnie by była elektrownia jądrowa zbudowana według standardów budynku mieszkalnego!).
Typ dokumentu zwykle wskazuje dokument, na podstawie którego planowana jest walidacja HTML, ale można go wybrać ze względów pragmatycznych, aby wybrać optymalny tryb przeglądarki.
XHTML5 może w ogóle nie mieć typu dokumentu, ale nadal będzie ważny.
Krótko mówiąc, walidacja to proces sprawdzania kodu i dostosowywania go do wybranego typu dokumentu (DTD).
Jak sprawdzana jest ważność?Ważność kodu HTML sprawdzana jest przez narzędzie zwane walidatorem.
Najbardziej znanym walidatorem w3c jest https://www.w3.org.
Walidator w3c przeprowadza kilka kontroli kodu.
Główne:
Aby sprawdzić ważność kodu CSS, istnieje walidator CSS - http://jigsaw.w3.org/css-validator.
Ważność kodu jest wynikiem mechanicznego sprawdzenia pod kątem braku formalnego OB, zgodnie z określonym zestawem zasad.
Musisz zrozumieć, że walidacja jest narzędziem, a nie wartością samą w sobie.
Doświadczeni programiści zazwyczaj wiedzą, gdzie można naruszyć zasady walidacji HTML lub CSS, a gdzie nie, i jakie są konsekwencje (lub nie) tego czy innego błędu walidacji.
Przykłady sytuacji, gdy witryna generuje nieprawidłowy kod:
Jest rzeczą oczywistą, że nie ma sensu ważność dla samej ważności.
Z reguły doświadczeni projektanci układów przestrzegają następujących zasad:
- W kodzie nie powinno być żadnych rażących błędów.
- Drobne można tolerować, ale tylko z uzasadnionych powodów.
Jeśli chodzi o akceptowalność błędów sprawdzania poprawności HTML/CSS:
Okazuje się, że działająca witryna prawie zawsze będzie miała jakiś rodzaj OV.
Co więcej, może ich być wiele.
Na przykład strony główne Google, Yandex i mail.ru zawierają po kilkadziesiąt błędów.
Nie zakłócają jednak wyświetlania stron w przeglądarkach i nie uniemożliwiają ich działania.
Wszystko, co napisano powyżej, dotyczy moich tematów.
W rezultacie całkowicie poprawny kod można uzyskać tylko poprzez kodowanie bardzo proste motywy, tj. te, które zawierają minimalną ilość funkcjonalności.
Po ukończeniu układu dowolnego z moich motywów zawsze sprawdzam go za pomocą walidatora i poprawiam wszystkie błędy, które można poprawić bez utraty funkcjonalności motywu.
Oznacza to, że jeśli istnieje wybór pomiędzy funkcjonalnością działającą a ważnością, wybieram funkcjonalność.
Jeśli tworzysz własne motywy, radzę zrobić to samo.
Z mojego punktu widzenia (a także z punktu widzenia większości projektantów układów) traktowanie walidacji HTML/CSS jako ostatecznej prawdy jest błędne. Obowiązkowe jest poprawianie tylko tych agentów, którzy:
- uniemożliwić przeglądarce prawidłowe wyświetlenie strony (niezamknięte i nieprawidłowo zagnieżdżone tagi).
- spowolnienie ładowania strony (nieprawidłowo podłączone skrypty).
- można naprawić bez zakłócania funkcjonalności motywu.
Mam nadzieję, że odpowiedziałem na wszystkie pytania dotyczące walidacji.
Myślę, że każdy, kto interesuje się tworzeniem i promowaniem stron internetowych, w taki czy inny sposób zetknął się z koncepcją ważności kodu. To wyrażenie oznacza napisanie kodu HTML witryny zgodnie z pewnymi standardami opracowanymi przez konsorcjum World Wide Web Consortium (W3C). Zgodność z zasadami określonymi w tym standardzie jest gwarancją kompatybilności między przeglądarkami, czyli prawidłowego wyświetlania utworzonej strony we wszystkich przeglądarkach, a także braku błędów wpływających na szybkość ładowania i inne parametry.
W nowoczesnego Internetu kryteria jakości układu strony internetowej zaczęły odgrywać ważną rolę, ponieważ teraz webmaster musi zapewnić prawidłowe wyświetlanie zasobu nie tylko na komputerach stacjonarnych i laptopach, ale także na wielu urządzenia mobilne z różnymi uchwałami.
Jak czysty i zorganizowany jest kod przez programistów, można sprawdzić sprawdzając ważność witryny, co odbywa się za pomocą specjalnego narzędzia sprawdzającego w oficjalnym zasobie W3C. Oto ogólnodostępny internetowy walidator kodu HTML, znajdujący się pod adresem validator.w3.org

Za jego pomocą możesz sprawdzić poprawność kodu HTML na trzy sposoby:
Wybór wymagana metoda przeprowadza się poprzez przejście do odpowiedniej zakładki: 
Zobaczmy, co się stanie, jeśli sprawdzimy aktualność jakiejś znanej witryny w Runecie, na przykład Habrahabr. Wklej go do pola analizy i kliknij przycisk „Sprawdź”. Po kilku sekundach walidator W3C da nam następujący wynik: 
Całkiem niezły wynik, bo sprawdzanie większości zasobów będzie generować dziesiątki, a nawet setki błędów.
Jeśli przewiniesz nieco stronę w dół, możesz dokładnie zobaczyć, gdzie sprawdzający znalazł błędy i ich opis, wskazując linie. Ponadto szczegółowo opisuje, na czym dokładnie polega problem, co ułatwia jego naprawę.
W każdym razie, jeśli na Twojej stronie zostały znalezione błędy, nie zmartwij się, ponieważ po pierwsze, tak naprawdę jest bardzo niewiele stron internetowych, które w pełni spełniałyby standard W3C, a po drugie, wszystkie błędy, które znalazł walidator HTML -code można poprawione.
Sprawdzenie witryny pod kątem ważności jej kodu HTML pozwala zrozumieć, czy wymaga ona poprawek i optymalizacji układu, ponieważ czystość i odpowiednia struktura kodu są ważnym elementem optymalizacji wewnętrznej. Wysokiej jakości układ semantyczny pozwala innemu kontrahentowi szybko zrozumieć cudzy kod, a także zwiększyć trafność tekstu i przyspieszyć ładowanie strony.
O celowości i konieczności wyszukiwania błędów walidacyjnych napisano już wiele artykułów, a powyżej pisaliśmy już o głównych korzyściach, jakie można uzyskać dostosowując kod swojej witryny zgodnie ze standardami W3C. Co więcej, takie działania będą równie przydatne zarówno w przypadku dużego portalu czy serwisu, jak i w odniesieniu do małego bloga czy wizytówki.